Keyword research schalen met SQL

Keyword Research schalen met SQL
Donderdag 1 december 2022 heb ik dit verhaal gedeeld als presentatie op de SEO Benelux in Antwerpen. Naast mijn presentatie was er ook een van Steven de Moor over het schalen van semi geautomatiseerde content en een van Steven van Duyse over RevOps - hoe marketing & sales bij elkaar te brengen. Het was super om uitgenodigd te zijn door Mathias en Jeroen om eens voor de groep mogen te staan.
Het onderwerp van mijn presentatie - die van de titel van deze post - leent zich goed om thuis/op kantoor na te doen. Sterker nog, dat is mijn hele intentie geweest van de talk. De talk als inspiratie en deze blog met meer details zodat je het rustig na kan doen.
De presentatie
Vind je het leuk mijn presentatie (nog) eens te bekijken? Voila! Hieronder heb ik deze ge-embed. Deze wordt aangevuld met video zodat mijn toelichting niet zal ontbreken.
Video walkthrough
Vul ik later aan :)
Deepnote bestand
Die vind je beneden aan de post.
Intro: SEO-ers spenderen soms wel een halve week in Excel

Als SEO werken we allemaal veel in Excel. Dat bleek wel in Antwerpen als antwoord op de vraag of er ook mensen zijn die méér dan 10 uur per week in Excel door brengen. We kunnen dus allemaal wel manieren gebruiken om ons werk minder afhankelijk te maken van Excel.
Daar zijn veel manieren voor te bedenken. Bijvoorbeeld door data standaard in een datawarehouse op te slaan en vanuit daar met de data aan de slag te gaan. Of meer data standaardiseren en vanuit rapportages direct inzichtelijk te maken.
Wat wij als SEO natuurlijk ook vaak doen is “iets met CSV bestanden”. Om een bepaalde analyse te doen bijvoorbeeld. Een typisch lineair proces hiervan is keyword research. Daar komen we allen mee in aanraking als SEO’s. Dat proces is al praktisch niet veranderd in de laatste 12 jaar en erg handmatig.
Nou, als er twee dingen zijn waar ik niet van houd dan is dat handmatig werk en inefficient met data werken. Ik leg daarom graag uit hoe ik:
- Keyword research standaardiseer voor teamwerk,
- Het proces overzichtelijker maak,
- Het eenvoudig deelbaar kan
Daarnaast is het ook de basis om het:
- direct aan te vullen met data vanuit BigQuery en/of API’s.
Waarom keyword research efficiënter maken?

Goede vraag. Het werkt toch? Ja, dat klopt. Maar het proces is totaal niet efficient. Data moet worden geëxporteerd uit je favoriete keyword tool zoals ahrefs. Vervolgens moet het schoon worden gemaakt, meerdere bestanden worden samen gevoegd en tot slot de categorisatie. Maar wat als je wilt samenwerken met een of meerdere category managers van je webshop? Of als je het binnen een agency wilt delen met collega’s of zelfs de klant? Daar is Excel toch echt niet handig voor. Dan komt het altijd weer neer op het samenvoegen van verschillende Excel bestanden. Iedereen doet het net wat anders… mega irritant.
In de aankomende slides zal er dan ook een nieuwe wereld open gaan. En het mooie is, het is helemaal niet moeilijk!
Welke versie kies jij: Excel of SQL

Excel is er bij ons SEO met de paplepel ingegoten. Serieus, van begin af aan van onze cariere werken we en worden we gegroomed om Excel masters te worden. Heel fijn, want na 12 jaar ben ik inmiddels behoorlijk kundig geworden. En met mij menig anderen.
Maar wat men niet weet is dat Excel juist helemaal niet de taal van data is. Laat staan van Big Data. Daar is SQL voor bedacht door IBM. In de jaren 70 al van de vorige eeuw! Het is dan ook niet gek dat Excel formules zo veel lijken op de SQL formules. Het is gewoon afgekeken van SQL.
SQL is dus al sinds begin der tijden de taal van data. Data dat in een database staat. Voor programmeurs een nobrainer wat vaak over het hoofd gezien door menig SEO. Juist omdat Excel er zo bij ons ingeramd is.
Excel is eigenlijk ook een soort database. De sheet heeft eenzelfde structuur als een tabel. Meerdere sheets maken een Excel bestand. Een Excel bestand lijkt dan weer op een database.
Daarom lijkt SQL ook zo veel op Excel formules. De principes zijn nagenoeg exact hetzelfde.
Werken met Excel is niet efficient

Dit is eigenlijk op alle processen van toepassing waarop je een vorm van data analyse doet. Of het nou rapportages zijn of dat je directe analyses doet op basis van screaming frog data in combinatie met andere bronnen. Bijna altijd moet er wel wat worden samengevoegd. Zal je altijd zien dat in GA de url’s als volledige worden ge-extract en in search console enkel de paden ná het root domain.
Heb je van 10 concurrenten voor keyword research alle keywords uitgedraaid? Alles zo ver dat het aan elkaar gekoppeld is? Minder belangrijke kolommen verwijderd? Alles naar een nieuwe sheet geplaatst om te ontdubben? Vervolgens met vlookup alle belangrijke kolommen er weer naast gezet? Top. Dan kan er nu begonnen worden aan het structureren van de data, het categoriseren. De volgende dag komt de klant of je deze 3 concurrenten ook nog even mee wilt nemen. Damn… irritant! En uitbesteden aan 3 collega’s? Succes straks met het samen voegen van alle informatie.
Kortom, dit proces is niet goed schaalbaar met Excel at all.
Bonus: Snel CSV bestanden mergen met de terminal
Wil je soms toch graag CSV bestanden die exact gelijk zijn even snel mergen op je laptop? Gebruik dan de terminal.
Stap 1: Plaats de CSV bestanden in 1 map
Stap 2: Open CMD op windows of de terminal op je mac en navigeer naar de map met CSV bestanden.
Stap 3: schrijf de volgende regel en druk op enter. Done!
Windows:
copy *.csv merged-bestanden.csv
Mac:
cat *.csv > merged-bestanden.csv
Note: De headers van ieder bestand worden ook meegenomen. Maar met het ontdubben van het finale bestand zal dit ook worden verwijderd :) Je zal zien dat zelfs dit eenvoudiger gaat met SQL in DeepNote.
De SQL toolset

Het aantal tools dat we nodig hebben blijft eenvoudig op 2. Je favoriete keyword research tool en Deepnote. Deepnote is een data notebook dat gemaakt is om in samen te werken. Waar bijvoorbeeld een Jupyter notebook speciaal is gemaakt voor Python, is Deepnote meer gericht op de data analyst. Met directe integraties met bijvoorbeeld BigQuery.
De meest gave feature van Deepnote? Het in kunnen laden van CSV bestanden en deze in kunnen lezen als dataframe. Aka de Excel sheet van Python 🙂. Letterlijk. Alle 30 andere features vind je op hun website.
Een Deepnote account aanmaken
Nu is het moment daar om aan de slag te gaan. Je kan alles vanaf nu met je favoriete keyword tool doen. Ik gebruik aHrefs. Het proces is hetzelfde met data uit andere keyword tools. Ik zal het later benoemen in de stap waar dit het meest belangrijk is om dan zelf even goed te kijken wat het verschil is.
deepnote.com - daar kun je een gratis account aanmaken.
Een keyword research map & project aanmaken
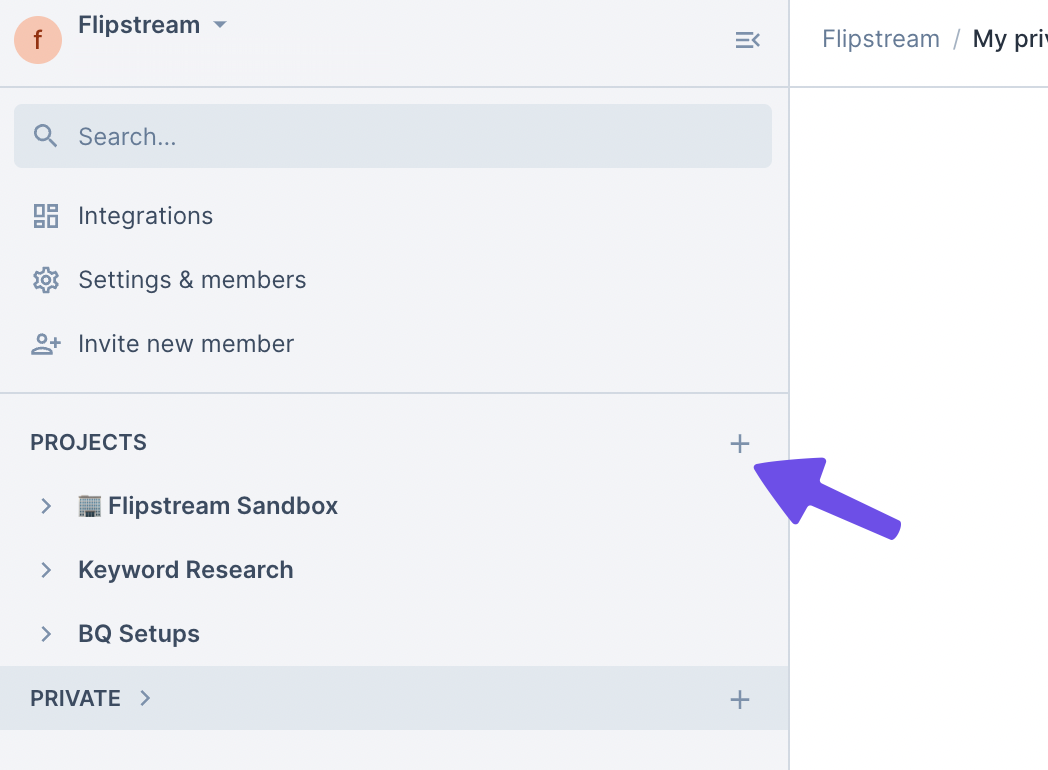
Zoals je hier ziet in mijn voorbeeld notes heb ik een project map aangemaakt voor keyword research. Dit kun je uiteraard naar eigen voorkeur inrichten. Binnen een map plaats je zo direct de notebooks waarin je werkt.
Een project + notebook aanmaken om je keyword research te doen
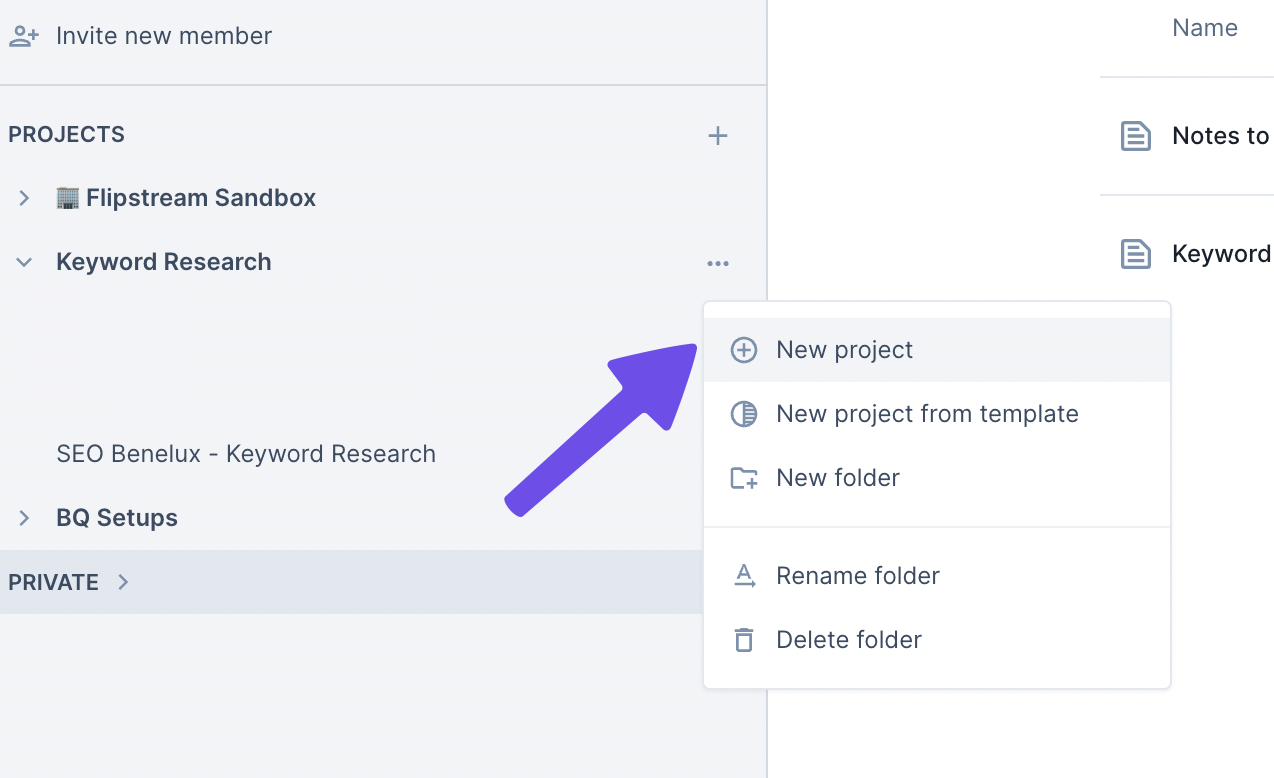
Lekker makkelijk, gewoon de drie dots aanklikken en vervolgens “New project”. New project from template is helaas nu nog beperkt tot templates van Deepnote zelf. In de toekomst gaan ze het wel mogelijk maken om zelf templates toe te kunnen voegen. Voor nu is de oplossing een project letterlijk als template te maken en deze te copy pasten of als voorbeeld te gebruiken.
Nu je een nieuw project hebt aangemaakt kun je de notebook gelijk een naam geven. Wat hier even een belangrijke is, is dat het project meerdere notebooks kan bevatten. Dat zie je hieronder in de afbeelding. De paarse omlijning in de breadcrumb is het project. De groene omlijning de notebook waar je in zit. Aan de rechterkant in het groen zie je alle notebooks die binnen het project beschikbaar zijn.
Voor het doen van keyword research is 1 notebook genoeg.
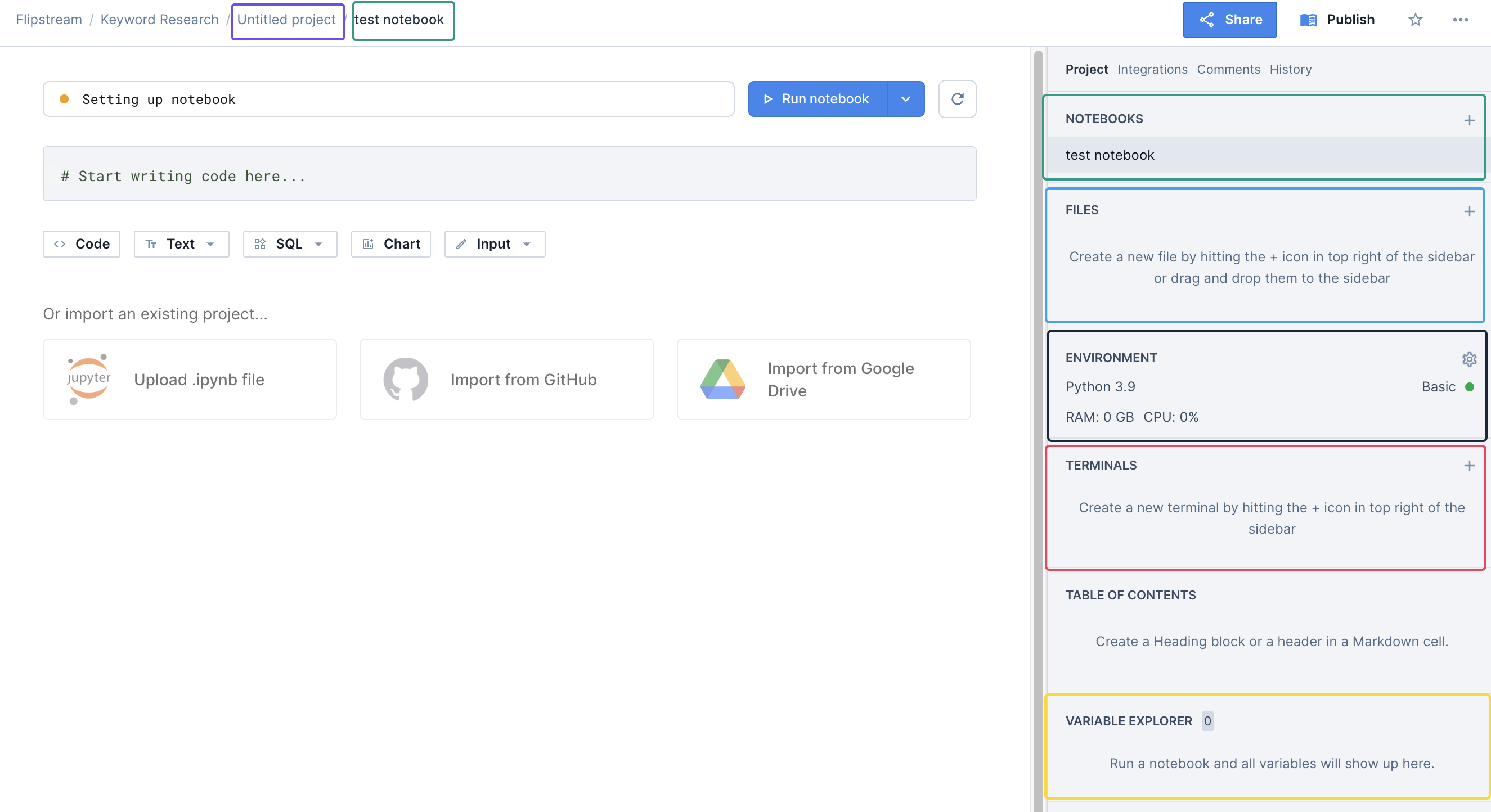
Wat zie je nog meer?
- Blauwe omlijning: Dit is waar je alle bestanden gaat zien die je hebt geupload
- Zwarte omlijning: Dit is de python en geheugen/cpu omgeving die gebruikt wordt voor deze notebook. Het gratis account is voorlopig voldoende. Maar voor zware berekeningen wil je wellicht upgraden.
- Rode omlijning: Wanneer je gebruik wilt maken van de interne command line doe je dat hier
- Gele omlijning: Sommige data zoals API sleutels wil je “verstoppen” - de namen waarin de verstopte sleutels zitten zul je hier kunnen vinden.
De zwarte, rode en gele vakken gebruiken we niet voor het doen van keyword research zoals in deze blogpost toegelicht. Het wordt wel bruikbaar wanneer je connecties met API’s wilt gaan toevoegen. Dat wordt een latere blogpost. Noem het de advanced versie :)
Stap 1: Upload je CSV bestanden
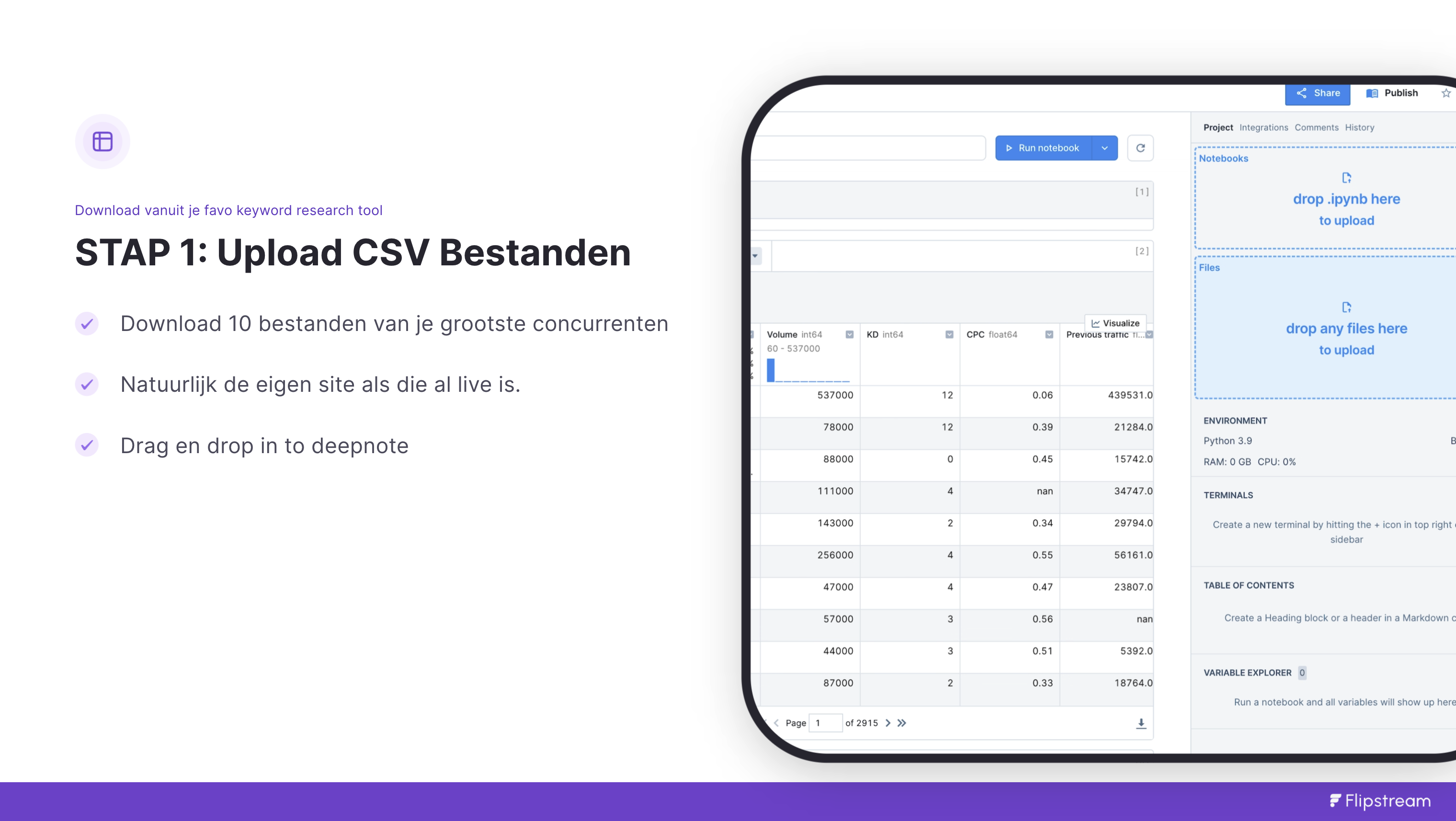
Heel simpel. Gewoon drag en drop. Nadat je de van een aantal concurrenten en de eigen site alle keywords hebt gedownload van bijvoorbeeld ahrefs.
Hieronder zie je de instellingen die ik in ahrefs heb gebruikt. Letterlijk alle keywords van het volledige domein exporteren.
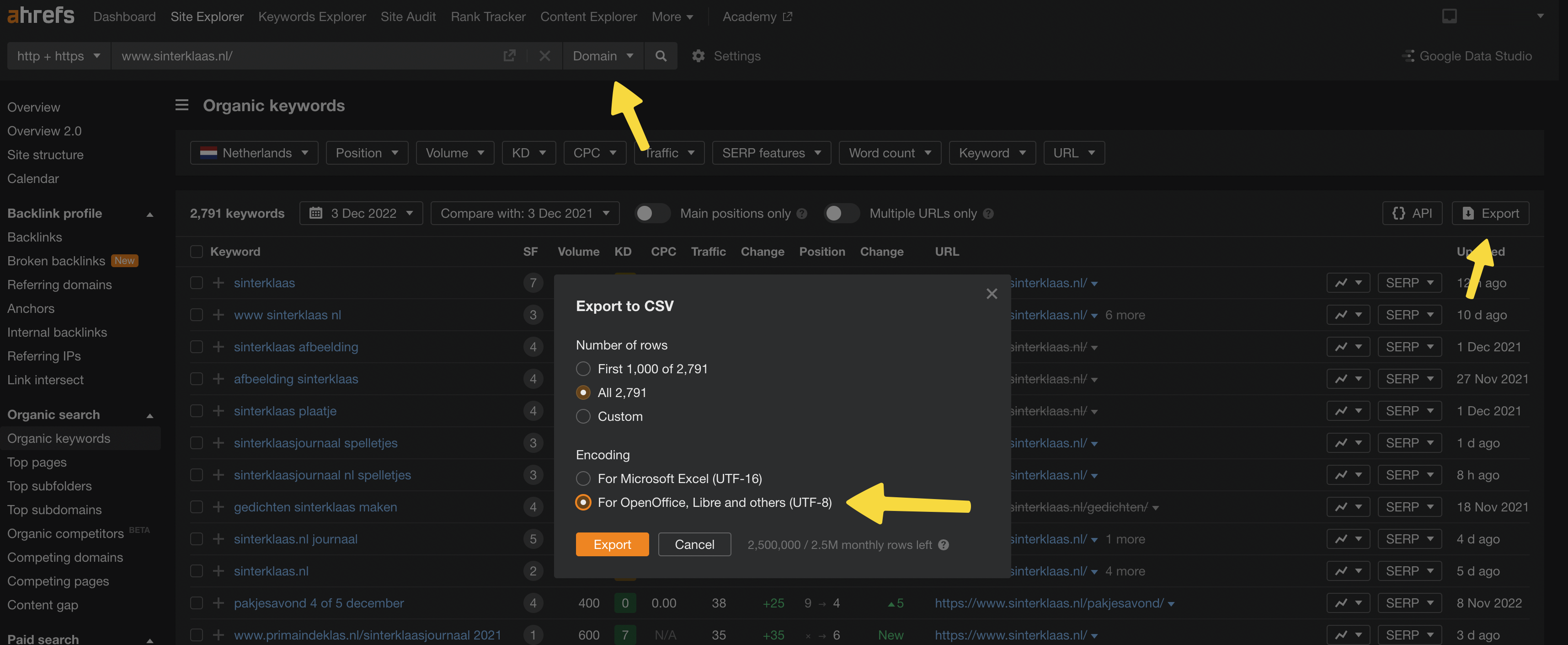
Dit doe je dan voor bijvoorbeeld 10 concurrenten en de eigen site. Verzamel alle CSV bestanden op 1 plek en vervolgens drag en drop je ze in de notebook in DeepNote die je net hebt aangemaakt.
Stap 2: Laad CSV als python dataframes
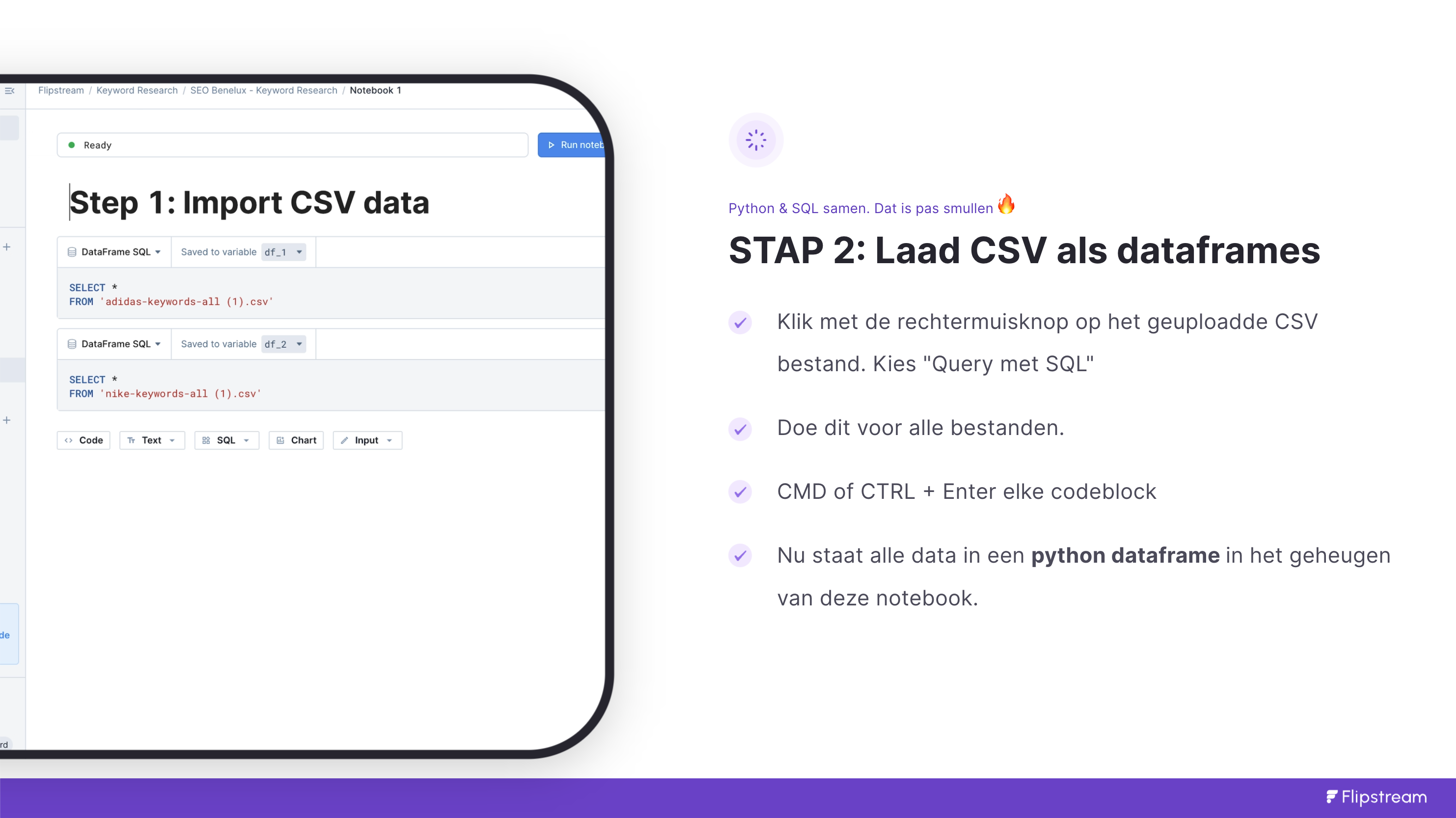
Ieder bestand laden we apart in in een DeepNote codeblock “Dataframe SQL”. Zo’n codeblock kun je handmatig openen door op SQL dropdown te klikken en dan het resultaat zoals in deze afbeelding aan te klikken.
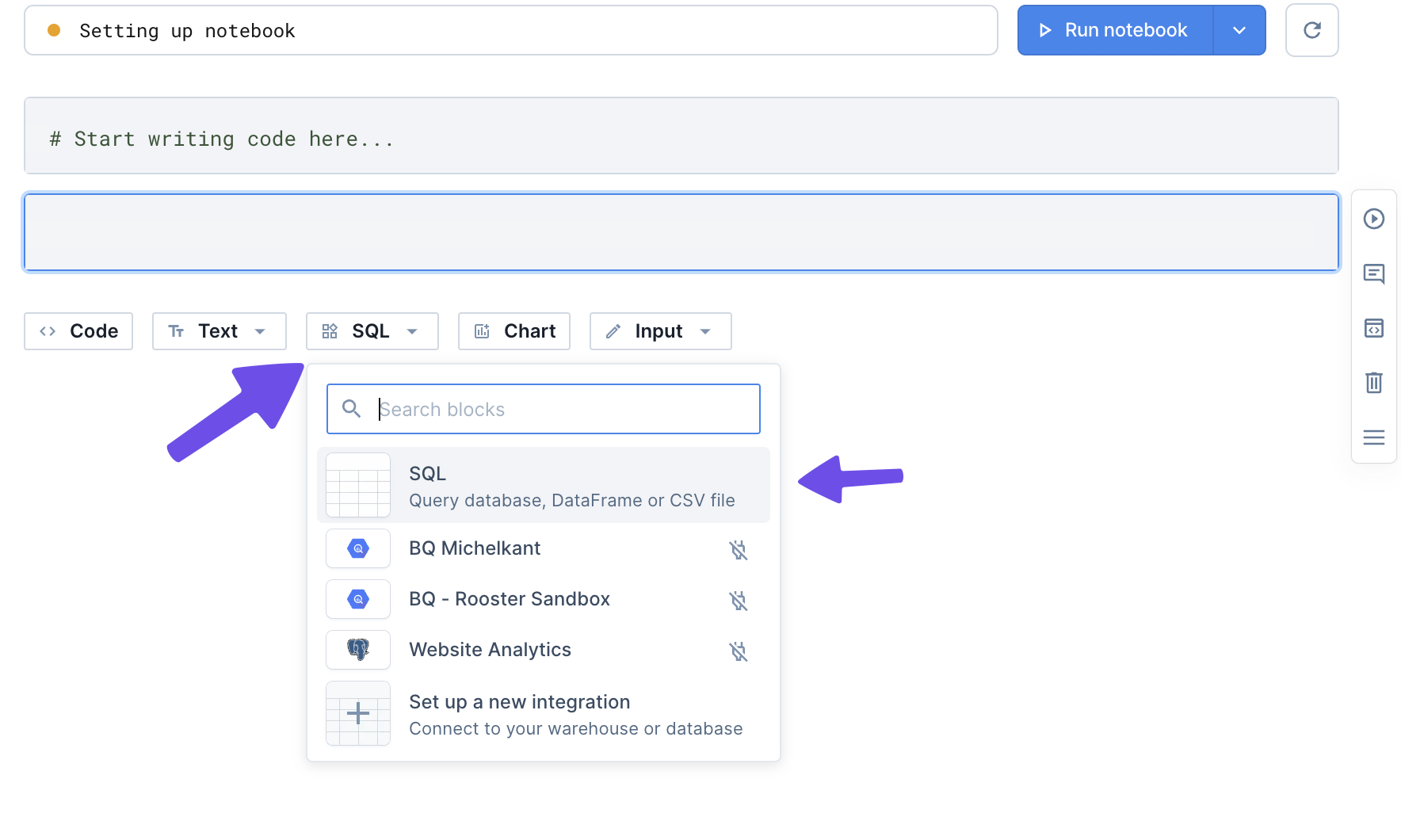
Je kan het ook eenvoudiger doen door op ieder bestand dat je in wilt laden met de rechtermuisknop te klikken en dan Query met SQL.
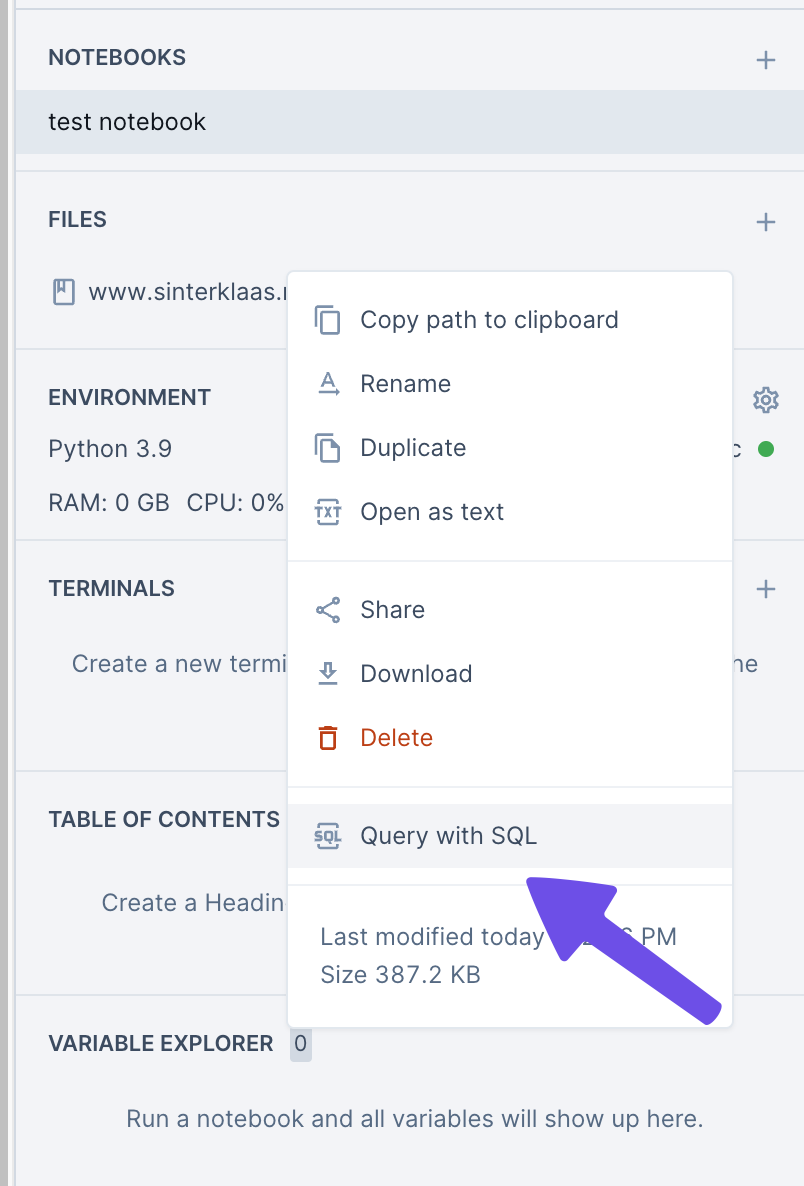
Dit zorgt er voor dat het voor je wordt uitgetypt. Wel zo handig, helemaal als je even snel meerdere bestanden in wilt laden. Hoef je ook niet zelf met de bestandsnamen aan de slag.

Stap 3: Union All - AKA Merge alle CSV bestanden
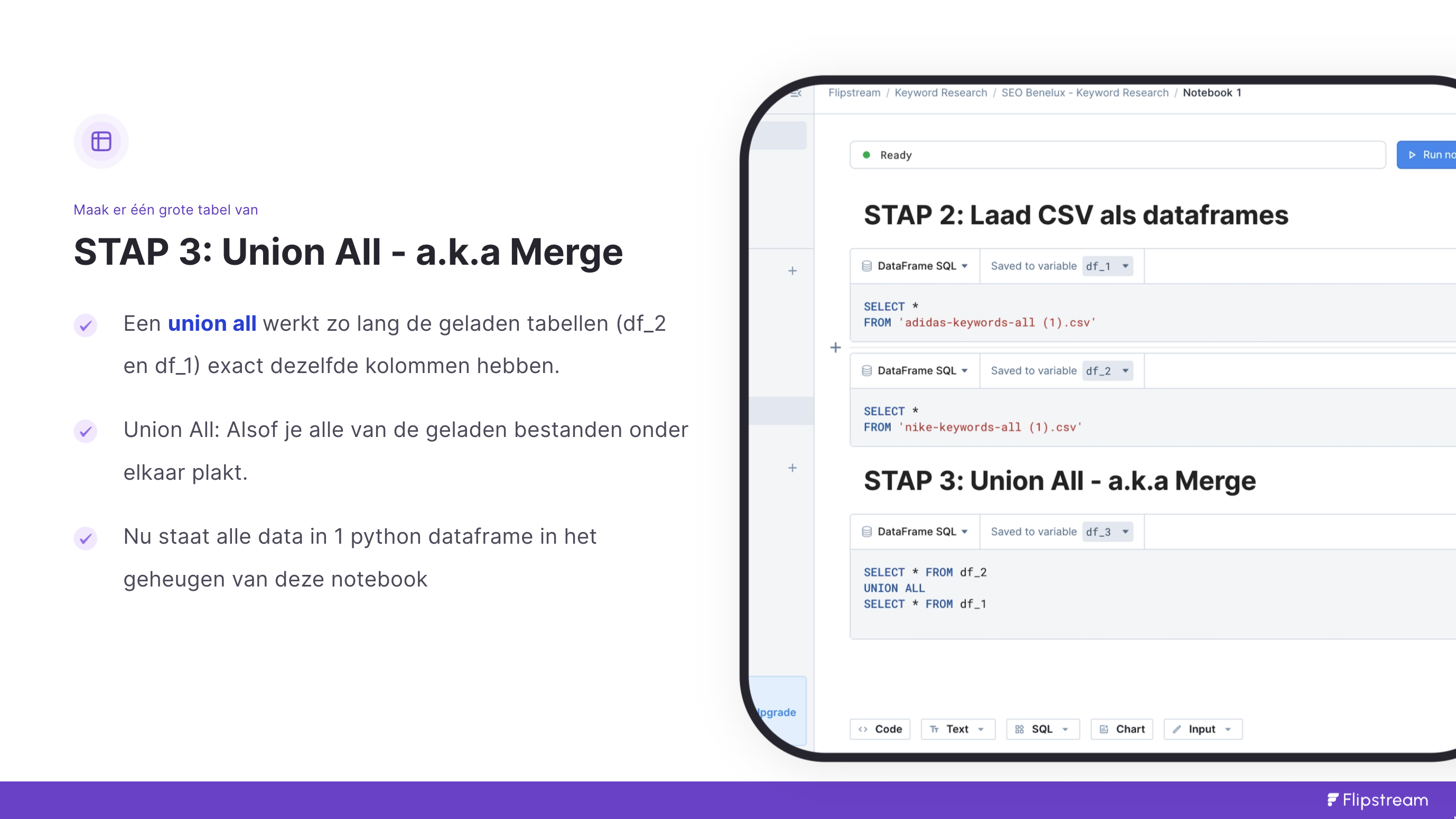
Dit doen we in 1 stap. Ook hier hebben we een “Dataframe SQL” blok nodig. Deze type je zelf uit.
Voor ieder bestand dat in de vorige stap is ingeladen zie j in het blok dat DeepNote het CSV bestand opslaat onder een variabel. In de voorbeelden van de presentatie zijn dat df_1 en df_2. In de code hoef je dus ook niet meer de bestandsnamen te refereren. Je refereert vanaf nu deze variabelen.
Codeblocks uitvoeren
Het is dan wel belangrijk om te onthouden dat die codeblocks waar die variabelen gemaakt worden wel eerst uitgevoerd moeten worden. Anders staan ze niet in DeepNote zijn geheugen. Dat doe je met run notebook bovenaan de pagina. Dan wordt elk blok van boven naar beneden in de juiste volgorder uitgevoerd. Je kan ook per block op command + enter of ctrl + enter te drukken. Activeer dan wel eerst de codeblock door erin te klikken.
Union ALL
We willen niet langer met 2 of 10 CSV bestanden werken, maar met 1. Dus gaan we voor elk bestand dat we willen mergen een UNION ALL doen. Een UNION ALL is lekker eenvoudig, wanneer je weet dat elk bestand toch hetzelfde is.
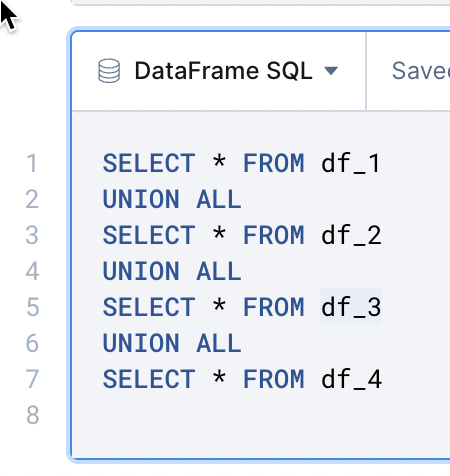
Stap 4: Filter de tabel

Nu willen we de nieuwste tabel die we hebben waarin alle data is gemerged filteren. Enerzijds duplicate keywords weghalen en anderzijds ook enkel relevante kolommen overhouden. Dat is wat je ziet in de image. De SQL is uitgeschreven als volgt:
SELECT
DISTINCT Keyword as keyword,
Volume as search_volume,
KD as kd,
“Current URL” as current_url
FROM df_3
De kolomnamen zijn natuurlijk afhankelijk van de data in het CSV bestand.
- Distinct is simpelweg “de-dupen” van data op basis van de kolom Keyword.
- Keyword AS keyword is het hernoemen van de kolomnaam zodat deze in kleine letter is. Dat is een SQL best practice.
- Volume as search_volume is ook het hernoemen van de kolomnaam. In SQL gebruiken we geen spaties.
- “Current URL” as current_url is hetzelfde. Omdat in het CSV bestand een spatie staat zijn de haakjes nodig. Dat willen we niet dus herschrijven we deze met een underscore en kleine letters.
Voor je nu deze code block uit dan zal je zien dat de kolomnamen aangepast zijn en ook zijn de duplicate keywords verwijderd.
Stap 5: Categoriseren
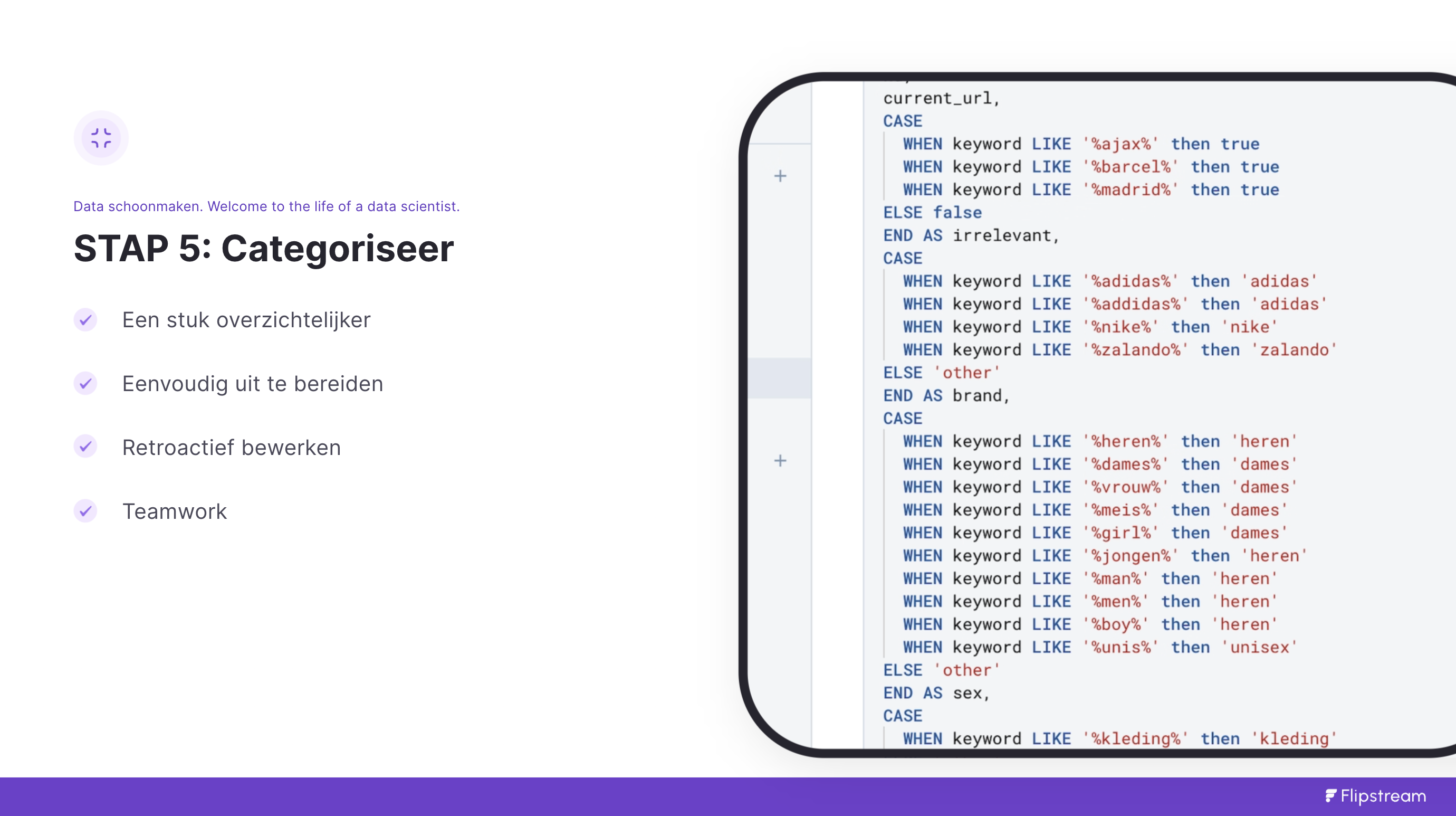
Dit is het onderdeel "where the magic happens". Van alle onderdelen is dit het meest vervelende in Excel. Het is onoverzichtelijk en vooral onduidelijk wanneer je wilt gaan samenwerken. Niet iedereen is gewend met nested formules te werken in Excel. Zoals je in de afbeelding al ziet is dat een stuk meer leesbaar in SQL.
SQL is expliciet en daarmee duidelijker dan Excel
Om keywords te categoriseren kijken we vaak of een bepaald woord voorkomt in het keyword. Denk aan typfouten, of simpelweg synoniemen of andere manieren om een woord te schrijven. Het kan ook zijn dat er meerdere opties zijn onder een bredere groepering. De typefout zie je in de afbeelding hierboven toegepast op de categorisatie van het merk Adidas. Je ziet ook in het voorbeeld hoe zowel mannen, heren en termen met boy als "heren" zijn gecategoriseerd. Open je de volledige DeepNote Notebook dan zul je zien dat bij category er een 60 varianten zijn gebruikt voor de kolom "category".
SQL is vrij expliciet geschreven. Waar je met Excel een if else continue moet nesten om meerdere manieren van een categorie te herkennen gaat dit met SQL regel voor regel een stuk netter. Veel eenvoudiger voor een niet-excel nerd om te zien hoe hij of zij mee kan helpen met de categorisatie.
IF ELSE Formules in SQL zijn CASE WHEN THEN

De CASE WHEN THEN formule in SQL is gelijk aan de IF ELSE formule in Excel. Bovenstaand voorbeeld in SQL ziet er als volgt uit:
Wat gebeurd er in de “WHEN keyword LIKE “%schoen%” hoor ik je vragen:
- WHEN is voor SQL “wanneer” X = TRUE.
- keyword LIKE “%schoen%” is waar naar wordt gezocht
- keyword is de kolomnaam waarin wordt gezocht
- de LIKE operator in SQL staat voor “bevat”
- kortom: keyword bevat iets
- Omdat we de LIKE operator gebruiken kunnen we zoeken naar een woord “%schoen%”. Als we alleen “schoen” zouden doen, wordt enkel gezocht naar die exacte match. De percentage tekens zorgen er voor dat er vanalles voor of na “schoen” mag staan. Je kan het ook als “schoen%” gebruiken of “%schoen”. Die eerste zal wel TRUE zijn op “schoen blauw” maar niet “blauwe schoen”. De tweede is andersom.
CASE WHEN THEN statements kunnen zo kort zijn als 1 regel of zo lang als je wilt.
Check deze loom voor een korte toelichting met video:
Het categorisatie proces
Nu begint het proces van categorisatie. Wat ik hier zelf altijd doe is steeds filteren op “other” van de kolom waar je mee bezig bent zodat alles wat matched op je CASE WHEN THEN niet meer in de tabel zit.
Dit is lastig om textueel uit te leggen. Dus check vooral deze korte loom:
Ik licht het ook even toe met deze code snippet voor als je video niets vindt :)
Wat je hier ziet is
- SELECT * From ( SELECT keyword.. etc) WHERE brand = ‘other’
dit is in feite hetzelfde als:
- SELECT * From df_2 WHERE brand = ‘other’
Maar dan met wat meer vrijheid om de tabel die genest is naar eigen voorkeur op te bouwen.
Geneste SQL Query
Dit is wat “meer geavanceerd” SQL waarbij een tabel is genest in de andere. Alles tussen regel 2 en 20 is genest. Hierdoor wordt de CASE WHEN THEN statement uitgevoerd in het geheugen en kunnen we deze met de WHERE clause op regel 22 en 23 filteren.
Ik leg het ook kort toe in deze loom:
Nu dat we alle data hebben gecategoriseerd is het tijd om de boel te visualiseren...
Stap 6: Visualiseren
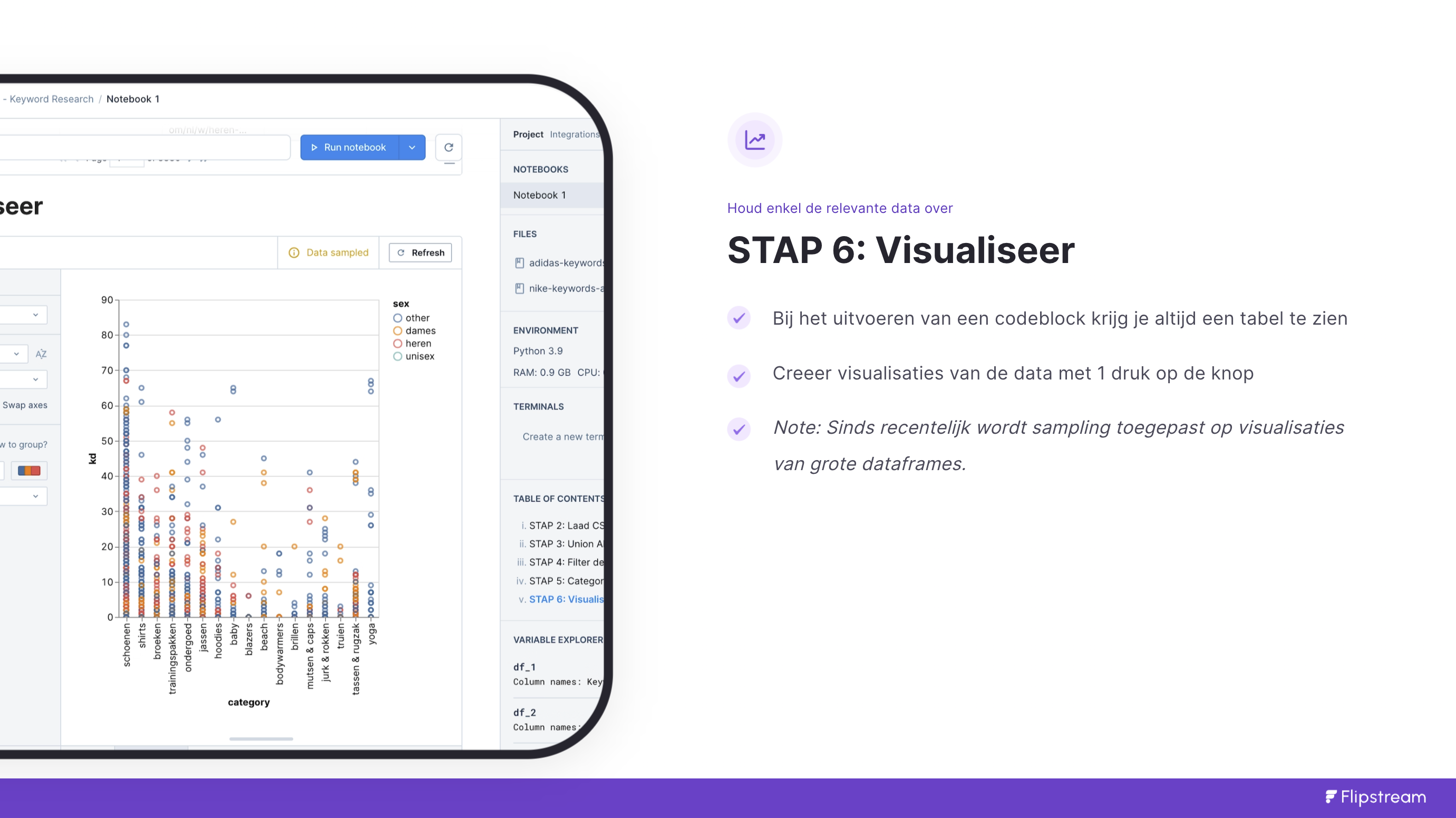
DeepNote maakt het eenvoudig voor ons om “even snel” de data te visualiseren. Daarvoor hebben ze een handige variant op een code block waarmee je in 10 seconden grafieken kan genereren.
Uitgevoerde codeblock direct visualiseren
Elke dataframe dat wordt gegenereerd omdat je een codeblock hebt uitgevoerd kan je met de knop rechtsboven direct visualiseren.
Handmatige optie
Klik op het plus teken en zoek de “Chart” optie zoals in deze afbeelding:
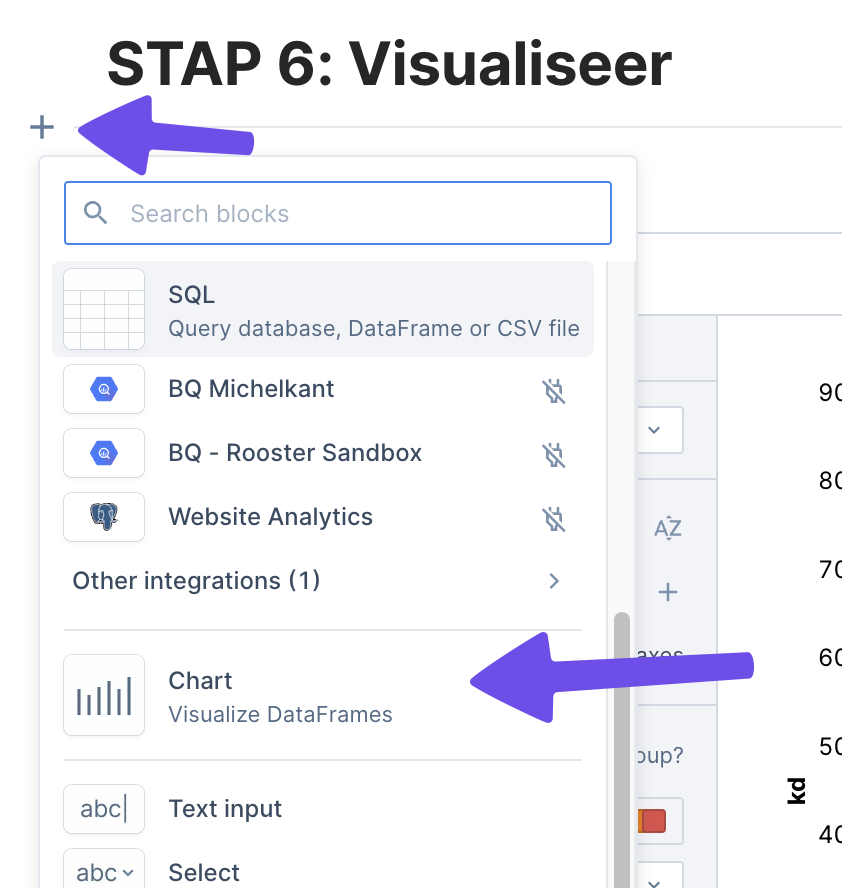
Vervolgens kan je zelf naar wens de grafiek samenstellen. Omdat het keyword research is hebben we keyword difficulty en search volume om mee te werken. Zou je werken met data waarin datums verwerkt staan dan kan je ook mooie lijngrafieken genereren om snel trends te zien.

Stap 7: Exporteer de keyword data

Het exporteren kan naar een CSV bestand zodat je er mee kan doen wat je wilt. Stel je hebt de categorisatie opgeslagen in df_5 dan is het enige dat je nog hoeft te doen het volgende:
SELECT *
FROM df_5
Je krijgt dan onderstaande tabel en met de knop rechts onderin kun je het als CSV bestand downloaden.
Bonus: Direct data uploaden naar Google BigQuery
Deze voeg ik later even toe!
Deepnote bestand
Het gehele Deepnote bestand kan je hier vinden:
Q&A
Is SQL moeilijk om te leren?
Nee. Het is net als Excel formules. Zoals je hebt gezien is het een stuk overzichtelijker. Binnenkort lanceer ik een online SQL cursus. Hiervoor kun je je via mijn website alvast registreren.
Let me know wanneer je dit gebruikt in je eigen werkzaamheden. De beste manier om met me in contact te komen is op linkedin en/of twitter.
Thanks for reading!

Gerelateerde artikelen
Voor als je graag door wilt lezen :)

SEO Market performance doelen

.jpg)
Van SEO als tactiek naar SEO als strategie
.jpg)
Hello World @ Michelkant.nl